
Keeping your knowledge up-to-date is very difficult in novel areas like deep learning. I know, I know... It's an amazing world but a very big one and fast moving too. Today I want to give you some insights on an advanced topic but where you can find some great novel ideas that you can use in your work or research.
Today we are going to talk about a (relative) new deep learning architecture, neural network or simply a model that performs classification over inputs with different nature (multi-modal), specifically images and texts in one-shot, i.e. a single pass through the network.
If you are not confident working with convolutional neural networks and attention models like transformer you'll probably feel a little overwhelmed, but don't scary! We all started like that. The first time that I read the "Attention is all you need" paper (Ashish Vaswani et al.) I didn't understand anything. I must read it at least three times to realize that I won't understand a fully new area (for me) with a single paper, I had to keep reading posts like this one, other papers and writing some code!
So don't be afraid, you only need to keep reading, being motivated and making things happen! At least, this post could give you some keywords that you can use to search related content and read more about this. One of the most important parts of learning is knowing what you don't know, so now I'm going to give you some keyword or key phrases to look for in Google and dig deeper!
Motivation
BERT has stolen the attention in the NLP landscape. Its amazing results (and the ones of the related models) are moving the entire field to use or at least try the transformer architecture. But the modern digital world is increasingly multimodal, textual information is often accompanied by other modalities like images or videos. Using the whole information can be very useful to increase the models performance. That was the objective of Douwe Kiela et al. and his team at Facebook AI Research. They develop a state-of-the-art multi-modal bitransformer (MMBT) model to classify images and texts.
Multimodal Bitransformer in simple terms
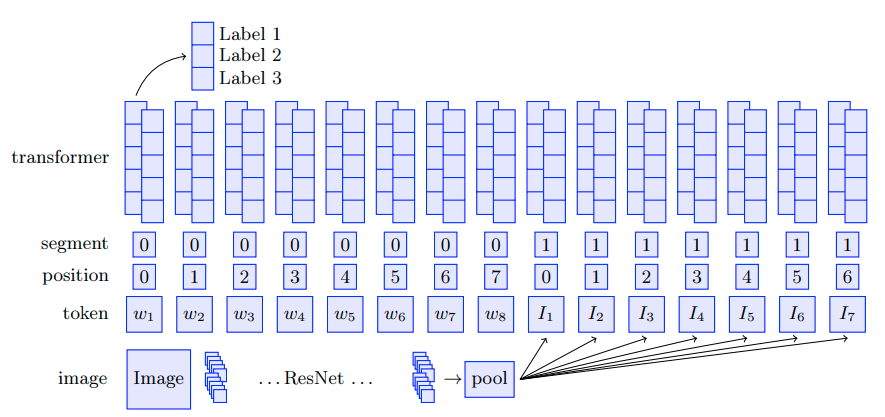
If you have worked with BERT you know that the inputs are the tokens of the texts, right? So how can we add the images? A naive but highly competitive approach is simply extract the image features with a CNN like ResNet, extract the text-only features with a transformer like BERT, concatenate and forward them through a simple MLP or a bigger model to get the final classification logits.
The authors argue that using the power of the bitransformer's ability to employ self-attention give the model the possibility to look in the text and the image at the same time, using attention over both modalities.
So, in simple terms, we are going to take the image, extract its features with a CNN and use that features as inputs (like tokens' embeddings!) for the bitransformer. That's what you can see in the image above, we give the model the sentence and the image as input to use attention over both modalities at the same time.
For me this was that kind of moment when you think "how I did not have this idea before?!". Is very very simple and at the same time very powerful.
That's all if you only wanted to know how this works. Now, for your next project that involves images and texts you can use this idea. If you want more details keep reading.
Advanced concepts
We know that the transformer model must be pre-trained in a self-supervised fashion and the image encoder (the CNN) must be pre-trained too. It's like a standard that (if you are not Google, Facebook or Nvidia that have hundreds or thousands of GPUs) you don't even think about training your own BERT model, you just apply transfer learning and fine-tuning to use them in your task. And obviously, that is what the authors did.
Image encoder
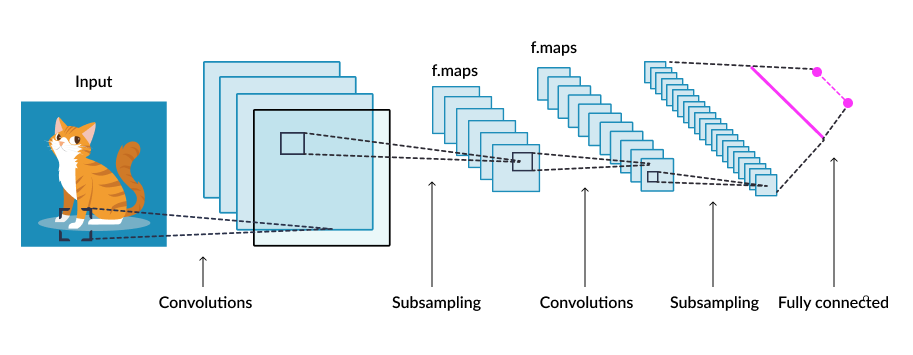
The authors used a ResNet-152 pre-trained over ImageNet. The network has a stride of 32 and generates a feature map with 2048 channels. This means that if you use a simple image of 320x320 pixels the output of the network will be a feature map of 10x10 and 2048 channels. In PyTorch notation you will have a tensor with shape (2048, 10, 10). This is the same for any of the ResNet models, the only difference is with the ResNet-18 that only generates 512 channels.
Over the feature map we can apply an adaptive average pooling to transform it and get HxW = K sections. In my implementation I used a final grid of (5, 5) that leads to 25 feature vectors, so we can think that our "image sentence" is composed of 25 "image section embeddings", but you can use the final size that fits your needs.
If we can make it simpler, we can think that our image encoder takes the grid size that you want, it applies the convolutions and average pooling over the image and generate a feature vector for each section. So if we use a grid of (5, 5) it will generate 25 embeddings, one for each section in the image.
Finally we use a simple linear layer to adjust the size of the image embeddings to fit the bitransformer's hidden size. In a normal BERT and ResNet configuration this is to transform our 2048 length vectors in 768 length vectors using the linear layer, because the BERT model has a hidden size of 768.
Multimodal transformer
One of the involved parts in the BERT training are the segment embeddings that are used to differentiate between the first sentence and the second sentence. A clever idea that the authors have was to use this same segment embeddings but to differentiate between the two modalities: text and image. This can be extended to any number of modalities, and you can make it work with the segment embedding to differentiate between the different type of inputs.
Finally the classification logits are computed using the same logic as any BERT instance, using a fully connected layer that receives as input the output vector of the [CLS] token (that is always the first token when you are using BERT) and transform it to the desired number of classes and a Softmax function with cross-entropy loss for single label outputs and for multi-label outputs you can use a Sigmoid with a binary cross-entropy loss. I usually use the Focal Loss in my projects that gives me better results (we can talk about it in another post).
Results
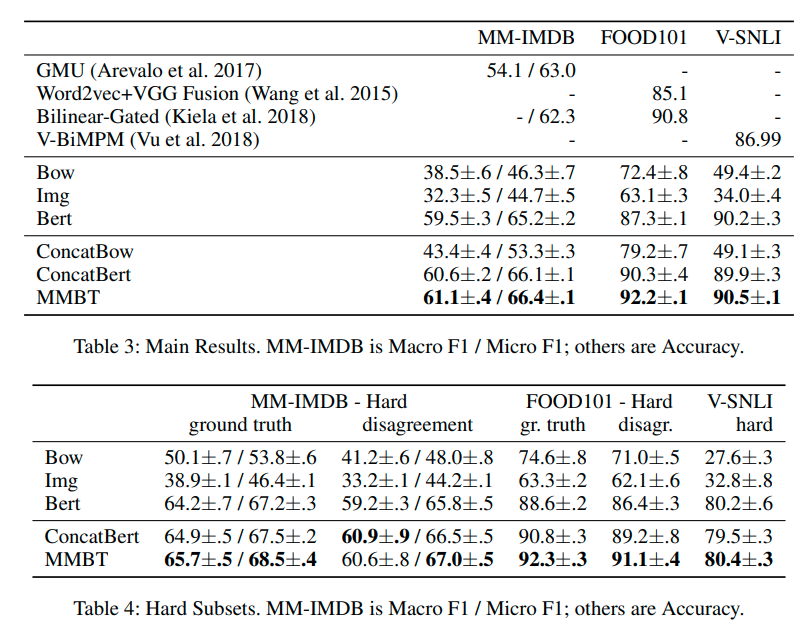
The authors tested the network over three different datasets: MM-IMBD, FOOD101 and V-SNLI. The baselines they used were:
- A simple bag of words (BOW) using the 300-dimensional word embeddings obtained with GloVe.
- A text-only model (BERT).
- An image-only model (ResNet-152).
- A concatenation of the feature vectors from BOW and ResNet.
- And the concatenation of the BERT feature vectors with the ResNet feature vectors.
And the results can be observed in the following tables (extracted from the paper):
Conclusion
We talk about a novel model that uses self-attention over inputs from different modalities (images and text) to perform classification. The clever idea of using the same transformer to use its attention modules and combine the embeddings of the different modalities lead to a simple but powerful model that obtains better results than only looking at the image or only looking at the text.
I've being using this model in production in my work and it performs pretty well! Indeed, better than my only BERT classifier and only ResNet classifier.
You can find more information in the paper and its github repository.
Have a nice day and keep reading, learning and happy coding!